Teh Cache - controlling our data layer
The problem the cache solves
Our main issue with alchemy was its reliance on the subgraph. This is a commonly used piece of the web3 stack which acts as a data layer that processes events off the blockchain and stores them essentially in a database. Alchemy used this service and we had many reliability issues. Although its expected to improve over time we decided that despite that possibility we need more for an app responsible for securing our entire treasury of over $100 million.
The cache takes this responsibility of our applications data layer and implements it in a rather novel way.
Explanation of implementation
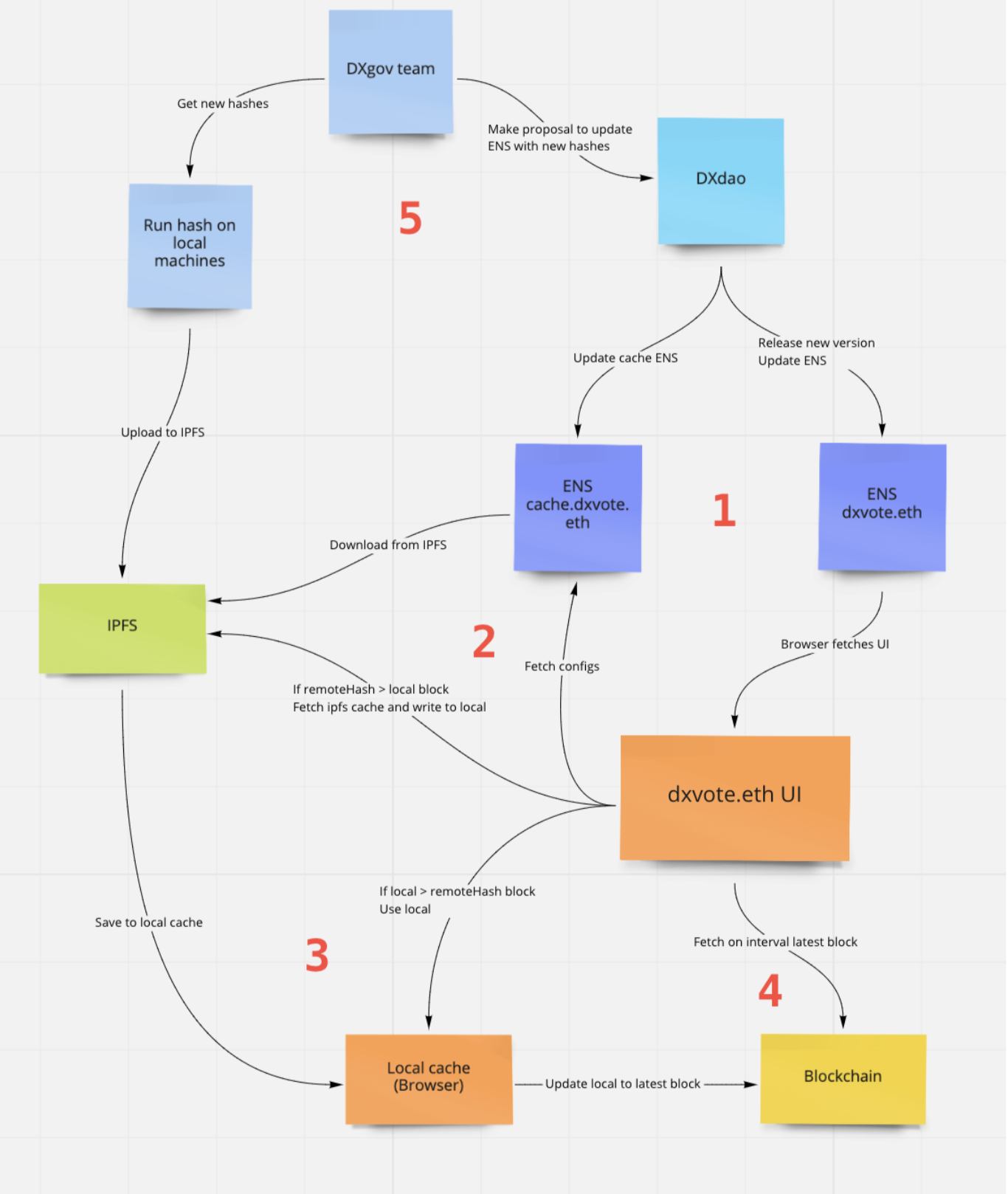
To understand the cache its important to understand how we use ENS in DXdao and DXgov (https://medium.com/dxdao/why-does-dxdao-use-ens-and-why-is-it-powerful-cb6f2e0e7769). We use ENS across all our apps to own and deploy our frontend (FE) applications. The way this works is that to update a frontend we create a proposal on-chain which if passed will allow the DAO to update the ipfs hash the ens domain points to, updating the FE.
With DXgov we take this a step further to own our data layer via ENS also. The cache itself is stored on ipfs and so we use a subdomain of our ENS (cache.dxvote.eth) to point to the most up to date version. This allows our data layer to be directly owned by the DAO, a key part of the decentralised architecture we have built.
So now how does the UI get the cache … also while we are at it … what IS the cache? The cache is essentially a large json object containing all the on-chain events relating to the governance contracts in our application. Since the size of the application is limited to only one DAO the volume of data is not huge and can be easily downloaded locally as opposed to a typical data solution where only necessary data would be downloaded.
There are of course limitations and scaling issues here, but once the need arises this could be solved by partitioning data into archival caches. One big advantage is that once written these events are set in stone and dont need editing due to being immutable on chain data.
However what is described here is only the data storage element, how then is the cache built and maintained? In the diagram at step 2 there are a number of operations happening on the left hand side of the UI block. This determines how the cache is fetched. The first step always performed is pulling the config file from cache.dxvote.eth, this gives the UI the last block number of the cache. For the initial load of the UI the cache will always be pulled from ipfs from the hash found in config. This is then stored locally in the browser’s local cache.
- When we start talking about a local cache of the cache things get complicated so here we define terms, “Remote cache” for ipfs stored and “local cache” for browser stored. The second time the UI is loaded the logic is more complex:
- If lastBlockNumber indicated from the config is smaller than the local cache, this is used as the remote cache has not been updated
- If the lastBlockNumber in config is higher than the local cache the remote cache will be downloaded and overwrite the local cache as it has been updated since the last visit
- Once the UI has the most up to date cache it can find, it then needs to make up the difference. This means going from the last block of the cache up to the most recent block on the network. This is appended to the cache for an up to date UI. The UI then also has a continuous fetch loop that checks the most recent blocks on a given chain for new events from the governance contracts. If any are found then the local cache is updated.
- This is great but if the remote cache is not updated then the UX for anyone not loading the application everyday to keep an up to date local cache is going to be very poor. This is where the DXgov team and anyone for that matter has the ability to update the remote cache. Since the data layer is controlled by an ENS anyone can submit a proposal to point it to a more up to date ipfs hash of a cache. And of course the tools for building the cache in a CLI is open source as with all of our code. To ensure no malicious caches are uploaded we require a reproducible deterministic hash to be reproduced on multiple machines before updating the ENS. This also has some scaling issues as the cache is currently updated every week but has a high reliance on the dev team. This could potentially be run automatically on a server (or 2) and only require humans to make the proposal on-chain.